


Ces deux méthodes reposent sur l'erreur fondamentale selon laquelle l'activité de conception s'arrêterait à la rédaction du cahier des charges et des spécifications détaillées, d'où le texte du programme se déduirait pour ainsi dire mécaniquement, ou en tout cas sans ambiguïté ni complexité majeure. Elles font donc porter l'essentiel de l'effort de leurs adeptes sur la précision et la clarté des documents de définition et de spécification du projet, avec le risque qui en découle (et souvent réalisé) d'un projet sur-spécifié.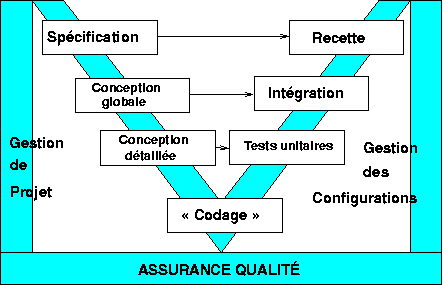
Figure 5.1 : Cycle de développement « en V » du logiciel, inspiré des industries de production matérielle.