| probabilité d'émission | quantité d'information |
| p1=1 | I(m1) = log10 (1/p1) = - log10 1 = 0 |
| p2=0,1 | I(m2) = log10 (1/p2) = - log10 10-1 = +1 |
| p3=0,01 | I(m3) = log10 (1/p3) = - log10 10-2 = +2 |
| ... | ... |
| H(S) = - |
|
pi × logapi |
Le graphe G, ou ABCDEFG, est tel qu'entre deux quelconques de ses sommets il existe au moins un chemin constitué d'arcs du graphe : un tel graphe est dit connexe. De surcroît, chaque sommet est relié par un arc à chacun des autres : c'est un graphe connexe complet. Chaque sommet est relié par un arc à chacun des n-1 autres sommets, et chaque arc joue le même rôle pour les deux sommets qu'il relie, G possède donc n × (n-1)/2 arcs.
La figure 6.2 représente un graphe H à sept sommets simplement connexe. Lorsque l'on parle de réseaux informatiques, il peut être commode de les représenter par des graphes. Les sommets sont alors généralement appelés noeuds du réseau, et les arcs, lignes ou liaisons.
La liaison peut être établie de deux façons. La plus simple est la liaison point à point, c'est celle que vous utilisez quand vous vous connectez de votre domicile à l'Internet avec un modem. Le chemin entre votre modem et le modem de votre fournisseur d'accès est une liaison point à point, d'ailleurs gérée par le protocole PPP (Point to Point Protocol, comme son nom l'indique), c'est à dire que vous pouvez considérer ce lien logiquement comme un fil unique, même si le réseau téléphonique traversé est, du point de vue téléphonique, complexe. Derrière le modem du fournisseur d'accès (FAI), il y a bien sûr un réseau complexe qui n'est sans doute plus point à point. La liaison point à point est généralement le procédé utilisé pour les liaisons à longue distance qui constituent un réseau étendu, ou WAN (pour Wide Area Network), par opposition à un réseau local (LAN, pour Local Area Network), c'est-à-dire cantonné à un immeuble ou à un campus. Ces notions de longue distance et de localité sont toutes relatives, par exemple les réseaux d'accès à l'Internet des distributeurs de télévision par câble sont des réseaux locaux à l'échelle d'une ville comme Paris (on parle alors de réseau métropolitain).
Combien de trames ont été perdues ou rejetées ? p+1=4. Pour que l'algorithme soit correct, il faut que l'émetteur garde en mémoire au moins les p+1 dernières trames émises, afin de pouvoir les réémettre. Plus p sera grand, plus le protocole sera rapide, mais plus il faudra de mémoire dans les équipements de transmission, ce qui est un compromis constant pour les performances des ordinateurs et autres machines à traiter de l'information.
Ainsi, un message électronique sera d'abord doté par votre logiciel de courrier des en-têtes applicatives, en l'occurrence telles que décrites par le RFC 822 (ce sont les lignes From:, To:, Subject:, etc. que vous lisez en haut des messages). Puis ce message conforme au RFC 822 se verra découpé en segments TCP, chacun doté de l'en-tête convenable (décrite plus bas). Chaque segment TCP sera empaqueté dans un datagramme IP qui possède lui aussi une en-tête. Et chaque datagramme sera expédié sur la couche liaison de données qui correspond au support physique, Ethernet par exemple.
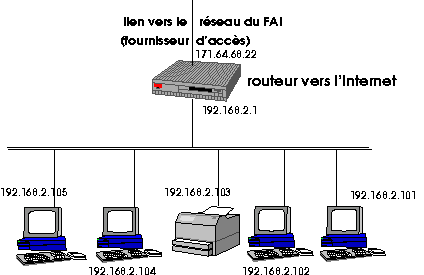
Les stations ordinaires ont une seule interface réseau, et donc une seule adresse de couche 2 et une seule adresse de couche 3 (dans les deux couches les adresses sont associées aux interfaces). Dans notre exemple les adresses (de couche 3) des stations vont de 192.168.2.101 à 192.168.2.105. Le routeur, par définition, possède au moins deux interfaces et donc deux adresses, ici vers le réseau local et vers le FAI et l'Internet. Dans notre exemple l'adresse intérieure est 192.168.2.1 et l'adresse extérieure 171.64.68.22.
Actuellement ce système assez rigide est souvent contourné et les classes sont de fait abolies par le système CIDR (Classless Interdomain Routing), qui instaure une situation hiérarchique plus simple où, à une feuille de l'arborescence, l'administrateur d'un réseau local fixe les quelques bits les plus à droite de l'adresse d'une interface, puis le FAI régional fixe quelques bits un peu plus à gauche, puis un organisme national encore quelques bits supplémentaires, et ainsi de suite jusqu'à l'ICANN qui distribue les bits de gauche à toute la planète, tout ceci en essayant de s'organiser pour que des machines topologiquement proches les unes des autres aient le plus de bits de gauche en commun afin de simplifier et d'abréger les tables de routage. Mais comme le RFC 791 est toujours en vigueur et que la plupart des adresses que vous rencontrerez au cours des prochaines années lui obéiront, autant comprendre cette syntaxe curieuse.
0123:4567:89ab:cdef:0123:4567:89ab:cdefIl y a des règles assez subtiles pour abréger cette représentation lorsqu'elle comporte de longues suites de bits à zéro, dont l'exposé ne nous semble pas indispensable, sachant que le lecteur curieux en trouvera le détail dans le RFC 2373 (http://www.ietf.org/rfc/rfc2373.txt).
IPv6 introduit d'autres modifications dans le traitement des adresses : si une adresse est toujours attribuée à une interface (plutôt qu'à un noeud), cette attribution est temporaire et les adresses sont réputées changer. Les chiffres les moins significatifs de l'adresse IPv6 sont calculés à partir de l'adresse de couche 2 (MAC) lorsqu'il y en a une.
Mais, pour poursuivre la comparaison avec le téléphone, dans un hôtel par exemple, seul le standard a un numéro de téléphone unique, et le poste de chaque chambre a un numéro local, à usage strictement interne, et qui peut très bien être le même que celui d'une chambre dans un autre hôtel : cela n'a aucune conséquence fâcheuse parce que le numéro de la chambre n'est pas visible de l'extérieur ; ceci permet parfaitement à l'occupant de la chambre d'appeler l'extérieur en donnant un code particuler (« composer le 0 pour avoir l'extérieur »), et de recevoir des communications en passant par le standard qui effectue la commutation vers la ligne de la chambre.
Figure 6.10 : Réseau sans NAT : les adresses des hôtes sont des adresses uniques et routées sur Internet.
La traduction d'adresse statique est simple, mais dans l'univers de la fin des années 1990 la pénurie des adresses IP (la version 4 du protocole IP comporte des adresses sur 32 chiffres binaires, ce qui autorise un maximum de 4 294 967 295 adresses uniques, mais en fait un peu moins compte tenu des contraintes sur la structure de ces adresses) a conduit vers d'autres réalisations, notamment la traduction d'adresses dite dynamique, et plus particulièrement vers une de ces méthodes dynamiques, dite IP masquerading (masquage d'adresse IP), aujourd'hui prédominante et que nous allons décrire bièvement (pour plus de détails et de références, cf. Wikipédia [75]). Avec NAT et le masquage d'adresse IP, seul le routeur possède une adresse routable, toutes les communications des noeuds internes sont vues de l'extérieur comme issues de cette adresse ou destinées à elle, et le tri est fait par le routeur au moyen d'une manipulation des numéros de port, de façon tout à fait analogue au travail du standardiste de l'hôtel que nous évoquions ci-dessus.
Figure 6.11 : Réseau avec NAT : les adresses des hôtes sont des adresses réutilisables. Le routeur d'entrée fait la traduction d'adresse. On notera que la modification du plan d'adressage alloue désormais un réseau /16 par sous-réseau, s'affranchissant de la limite des 254 adresses possibles avec un /24.
En anticipant sur la section suivante, disons qu'une connexion TCP est identifiée par la quadruplet {adresse IP de destination, numéro de port de destination, adresse IP d'origine, numéro de port d'origine}10. En général, dans le paquet qui initie la connexion, le numéro de port de destination obéit à une convention (par exemple 80 pour l'accès à un serveur WWW), et le numéro de port d'origine est quelconque, supérieur à 1024, et choisi de façon à former un couple unique avec l'adresse d'origine. Lorsque le routeur recevra un tel paquet, où l'adresse d'origine sera une adresse NAT non routable, il remplacera cette adresse par sa propre adresse, éventuellement il remplacera le numéro de port d'origine par un autre, s'il a déjà utilisé ce couple { adresse, numéro de port} pour une autre traduction, et il conservera dans une table la correspondance entre ce couple {adresse, port} envoyé sur l'Internet et celui du poste émetteur, ce qui permettra, au prix donc d'une traduction, d'acheminer les paquets dans les deux sens.
Figure 6.12 : Réseau avec NAT et masquage d'adresse IP : seule l'adresse de l'interface externe du routeur est utilisée ; le multiplexage/démultiplexage des adresses IP internes se fait grâce aux numéros de ports (modifiés par le routeur).
La figure 6.13 montre l'organisation hiérarchique de l'espace de noms de l'Internet. Chaque noeud de l'arbre, représenté par un cercle, comprend un label, qui peut avoir jusqu'à 63 caractères de long, et pour lequel les lettres minuscules et majuscules ne sont pas distinguées. Le nom de domaine d'un noeud s'obtient en construisant la séquence de tous les labels des noeuds compris entre le noeud considéré et la racine inclus, séparés par des points, comme par exemple vera.sophia.inria.fr.
Dans de nombreux cas, RIP réussit brillamment à reconfigurer automatiquement un réseau endommagé et à lui rendre sa connectivité. RIP doit aussi éviter des pièges, comme celui tendu par la situation illustrée par la figure 6.14, où l'on voit, à l'état initial, un noeud B qui accède au réseau R par l'intermédiaire du noeud A.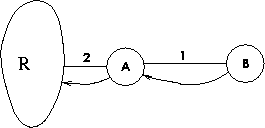
Pour surmonter les difficultés énumérées plus haut et atteindre ces objectifs, un système poste à poste comporte quatre composants fondamentaux :

Figure 6.19 : Une passerelle (gateway) va permettre au nouvel arrivant de découvrir l'adresse IP d'un membre déjà connecté.

Figure 6.20 : Ici deux noeuds confinés par des coupe-feux (firewalls) essaient néanmoins de construire une voie de communication entre eux, mais le procédé retenu est rudimentaire et peu efficace.