Finalement il apparaît que les plus fidèles disciples de l'équipe Multics furent les ingénieurs d'Intel. Depuis le modèle 80286 jusqu'à l'actuel Itanium les processeurs de la ligne principale d'Intel disposent d'une gestion de mémoire virtuelle à adressage segmenté. Aucun système d'exploitation implanté sur ces processeurs, que ce soient ceux de Microsoft ou les Unix libres FreeBSD, NetBSD ou Linux, ne tire parti de ce dispositif pour unifier les gestions de la mémoire virtuelle et de la mémoire persistante (le système de fichiers) ; les premiers sont contraints à la compatibilité avec leurs ancêtres... et les Unix aussi.
| 1 ÷ 3 | ® | 3 × 0 +1 |
| 4 ÷ 3 | ® | 3 × 1 +1 |
| 7 ÷ 3 | ® | 3 × 2 +1 |
| 10 ÷ 3 | ® | 3 × 3 +1 |
| 13 ÷ 3 | ® | 3 × 4 +1 |
| 16 ÷ 3 | ® | 3 × 5 +1 |
| 4 º 1 mod3 |
| 7 º 1 mod3 |
| ... |
| 4+7 (mod 3 ) | = | (4+7) mod3 |
| = | 11 mod3 | |
| = | 2 mod3 |
| 4 × 7 (mod 3 ) | = | (4 × 7) mod3 |
| = | 28 mod3 | |
| = | 1 mod3 |
| 4 × 7 (mod 12 ) | = | (4 × 7) mod12 |
| = | 28 mod12 | |
| = | 4 mod12 | |
| 4 × 6 (mod 12 ) | = | (4 × 6) mod12 |
| = | 24 mod12 | |
| = | 0 mod12 |
| Z3* | = | {1, 2} |
| Z12* | = | {1, 5, 7, 11} |
| Z15* | = | {1, 2, 4, 7, 8, 11, 13, 14} |
| 5 × 5 mod12 | = | 25 mod12 |
| = | 1 mod12 | |
| 7 × 7 mod12 | = | 49 mod12 |
| = | 1 mod12 | |
| 11 × 11 mod12 | = | 121 mod12 |
| = | 1 mod12 | |
| 7 × 13 mod15 | = | 91 mod15 |
| = | 1 mod15 |
| 53 mod11 | = | 125 mod11 |
| = | 4 |
| a | = | WA modP |
| = | 73 mod11 | |
| = | 343 mod11 | |
| = | 2 |
| b | = | WB modP |
| = | 76 mod11 | |
| = | 117 649 mod11 | |
| = | 4 |
= .9@percent
| bA modP | = | 43 mod11 |
| = | 64 mod11 | |
| = | 9 |
| aB modP | = | 26 mod11 |
| = | 64 mod11 | |
| = | 9 |
| B = |
|
| C=P(M) = Me modn |
| C=P(19) = 197 mod33 = 13 |
| T=S(C) = Cd modn |
| T=S(13) = 133 mod33 = 19 |
| S(C) | = | Cd modn |
| = | (Me)d modn | |
| = | Me.d modn | |
| = | M modn |
cn=Jacques Martin, ou=Groupe Système, ou=Division Informatique, o= Compagnie DupontLa forme des certificats découle également de la normeX500, et elle obéit à la norme X509.
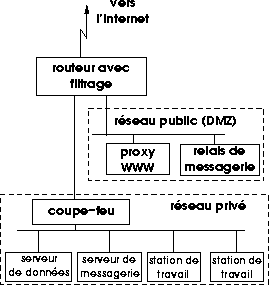
Il est prudent que les serveurs en zone publique contiennent aussi peu de données que possible, et même idéalement pas du tout, pour éviter qu'elles soient la cible d'attaques. Ceci semble contradictoire avec le rôle même d'un accès à l'Internet, mais cette contradiction peut être résolue en divisant les fonctions. Ainsi pour un serveur de messagerie il est possible d'installer un relais en zone publique qui effectuera toutes les transactions avec le monde extérieur mais transmettra les messages proprement dit à un serveur en zone privée, inaccessible de l'extérieur, ce qui évitera que les messages soient stockés en zone publique en attendant que les destinataires en prennent connaissance. De même un serveur WWW pourra servir de façade pour un serveur de bases de données en zone privée. Ces serveurs en zone publique qui ne servent que de relais sont souvent nommés serveurs mandataires (proxy servers en anglais).